AMP论文分析
AMP论文分析
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
引入
先从从模仿学习IL(Imitation Learning)说起。正常的强化学习RL(Reinforcement Learning)过程是“环境互动+最大化认为人为设计的奖励函数=最优Actor”
逆强化学习IRL(Inverse Reinforcement Learning)则没有奖励,取而代之的是“环境互动+最大化从专家数据学到的奖励函数=最优Actor”
GAIL(Generative Adversarial Imitation Learning)是使用GAN(Generative Adversarial Network)的IRL,即训练一个生成器 $G$ ,它从一个普通的分布逐渐生成与现有数据分布相似的分布。GAIL的数据集(参考运动)是 $\{(s,a)\}$ 。同样,我们希望我们的 Actor 能够模仿专家,即 Actor 产生的轨迹(的分布)与专家产生的轨迹(的分布)相似。GAN中的生成器和判别器这里不再赘述。reward是鼓励policy的行为和数据集里面的 $(s,𝑎)$ 对尽可能像。
AMP目标
本文的目标是训练一个agent,让其完成某个目标(Goal),同时保持某种风格(Style),其中风格由expert dataset或者demonstration dataset提供。本文混合了目标实现和模仿学习,其中模仿学习使用对抗性方式学习对给定风格的遵守,AMP中的A(Adversarial)就是对抗性。
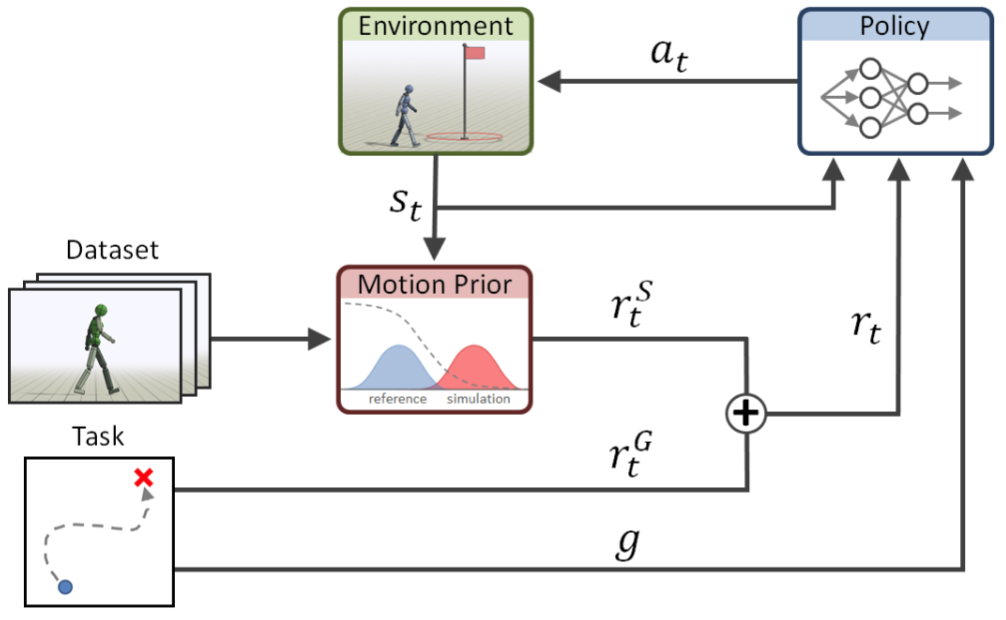
奖励函数由两部分组成,一部分是目标奖励 $r_t^G$ ,另一部分是风格奖励 $r_t^S$ ,通过计算两者的加权和得到总奖励:
目标奖励
agent可以是人形机器人,也可以是四足机器人或者霸王龙。目标奖励函数 $r_t^G$ 描述到达目标的程度,其根据目标来设计,如接近某个目标点或击打一个物体,这部分内容在附录中有详细介绍。作者针对不通的目标设计了很多奖励塑造,比如击打目标物体的任务,如果离目标很远则跑过去,如果离目标很近则切换到行走,如果与目标足够近则击打目标。agent观测环境得到state,生成action来实现目标。这里的任务设计是经典的策略梯度方法RL。
风格奖励
数据集可以是动捕数据,也可以从已经学会的Policy中得到。数据集只提供运动的风格,而不提供如何实现目标。风格奖励 $r_t^S$ 描述遵守数据集中风格的程度,由运动先验(Motion Prior)进行判断,运动先验由GAN训练得到,经典的GAN Loss为:
这里首先简单介绍一下标准的GAN(Generative Adversarial Network),就是要训练一个生成器和一个鉴别器。生成器接收随机噪声作为输入,从一个普通的分布逐渐生成与数据集分布相似的分布。鉴别器的任务是需要区分数据集中已有的 $(s,a)$ 和生成器产生的 $(s,a)$ ,最后的目标是欺骗鉴别器:生成器产生的数据来自数据集。
本文中使用的GAN与传统GAN有一些改动。首先对于Agent,基于当前状态 $s$ ,采取动作 $a$ ,得到下一个状态 $s’$ 。但是数据集中只有连续的状态 $s_i$ 而并没有对应的 $a_i$ ,所以只使用上述三个参数中的 $s$ 和 $s’$ 来描述一次Transition,故GAN的状态对变为 $(s,s’)$ 。除此之外与经典GAN不同的是,本文中的生成器其实就是Policy,输出也是 $(s,s’)$ ,所以鉴别器的任务就变成了区分数据集中已有的 $(s,s’)$ 和Policy产生的 $(s,s’)$ ,最后的目标同样是欺骗鉴别器:Policy产生的真实数据来自数据集。这里的鉴别器实际上就是运动先验。
本文使用的Loss也与经典GAN不同,使用了最小二乘鉴别器(Least-Squares Discriminator),使用平方损失,这样可以获得更好的梯度:
上述公式的意思就是:如果数据来自真实数据 $M$ , $D(s,s^{\prime})$ 会接近1;如果数据来自Policy $\Pi$ , $D(s,s^{\prime})$ 会接近-1。
使用鉴别器的输出来设计风格奖励函数:
可以看出,风格奖励被限制在0到1之间。如果鉴别器的输出 $D(s_t,s_{t+1})=1$ ,此时奖励达到最大(1),即鉴别器认为 $(s,s’)$ 来自数据集。换句话说就是,当Policy设法产生了鉴别器认为是来自数据集的Transaction $(s,s’)$ ,他就会获得最大奖励。
总体流程
总结一下,上述训练过程就是policy在试图达到目标的同时去欺骗鉴别器“我就是数据集”;鉴别器则在试图区分开Policy产生的数据和数据集中的数据。
上述过程可以用伪代码来表示。1-5行是初始化各种buffer;7-8行使用policy产生m步的轨迹;第10行把transitions给判别器,状态对使用特征函数来 $\Phi$ 表示;11行根据上面的公式,使用鉴别器的输出计算风格奖励;12行通过计算目标奖励和加权奖励的加权和得到总奖励;15行将得到的轨迹存到reply buffer;20行使用reply buffer来更新鉴别器;22行更新价值函数和策略。

梯度惩罚
GAN训练可能不稳定,使用梯度惩罚可以稳定训练
上面第三行惩罚了判别器出来的梯度范数
动作组合与过渡
AMP的另一个强大之处是经过学习之后可以组合数据集中的动作,也可以在多个动作之间自动过渡。比如数据集中只有独立的行走或奔跑而没有从行走到奔跑、从奔跑到行走这种组合,中间的转换过程则由策略自己学习。
这种多个动作的组合需要用权重来控制,比如举起手行走,如果举手的权重过小,则几乎无法行走;如行走的权重过小,则无法举手。
参考文献:
https://www.youtube.com/watch?v=P38FZrbNHV4
https://blog.csdn.net/weixin_41960890/article/details/123644185
https://zhuanlan.zhihu.com/p/503357084#ref_1
https://xbpeng.github.io/projects/AMP_Locomotion/index.html
https://xbpeng.github.io/projects/DeepMimic/index.html
https://xbpeng.github.io/projects/AMP/index.html
https://arxiv.org/abs/2203.14912
https://rofunc.readthedocs.io/en/latest/lfd/RofuncRL/AMP.html
 微信
微信- 支付宝


